

We have learned many things about OpenAI’s ChatGPT since it went live nearly a year ago:
- ChatGPT is really good at writing cover letters and resumes. Like answering a law school exam (“IRAC”) a cover letter is an exercise in whether you can format text appropriately, which falls directly in ChatGPT’s wheelhouse. This “talent” also helped ChatGPT pass the bar exam without BarBri or Kaplan.
- If you are into dad jokes,ChatGPT is your jam! Here’s an example:Why did the lawyer become a gardener?
Because they wanted to learn how to “weed” out the truth! - ChatGPT has a tendency to get creative with legal precedent, citing cases that don’t actually exist, which in some circles is frowned upon. Yes, lawyers wishing to maintain an active status in their state bar should NOT use ChatGPT to draft briefs and file them without verifying the content.
Good news for legal professionals! While ChatGPT is a diploma away from being able to get a law firm job, its inability to separate truth from fiction will ultimately lead to its disbarment despite its keen sense of humor. Your jobs are safe… for now.
Good news for legal professionals! While ChatGPT is a diploma away from being able to get a law firm job, its inability to separate truth from fiction will ultimately lead to its disbarment despite its keen sense of humor. Your jobs are safe… for now.
Be warned however, this is only the first iteration of ChatGPT, and it was trained on literally everything. Someone somewhere is training a large language model using Generative Pre-trained Transformer (GPT) technology on statutes and case law, which will be a powerful partner for lawyers.
In this article, we’ll take a closer look at ChatGPT, how it was trained, and the services it currently provides. We’ll also pontificate on how this technology will eventually impact the practice of law.
ChatGPT: What is it?
To answer this question, I went to the source: ChatGPT itself.
According to ChatGPT, ChatGPT (“GPT”) is an “advanced language model developed by OpenAI,” whose purpose is to assist and engage in conversations with users.” GPT was “trained on a wide range of topics and has access to a vast amount of information up until September 2021.” It was trained using unsupervised learning. Which means that GPT was exposed to “a massive amount of text data from diverse sources such as books, articles, websites, and other written material,” which was used to teach it “how language is structured and how words and phrases relate to each other.”
“The training process involved predicting the next word in a sentence based on the context provided by the previous words,” says GPT. By learning from billions of sentences, it gained an understanding of grammar, facts, reasoning abilities, and some degree of world knowledge. This training enables GPT “to generate coherent and contextually relevant responses when given input in natural language.”
Importantly, GPT notes that it strives, “to provide accurate and helpful information.” However, it “can still generate incorrect or misleading responses. Therefore, it’s always a good idea to independently verify any important information I provide.”

A Midjourney rendering of a conceptual description of ChatGPT’s as described by CharGPT.
GPT does not know the exact number of documents that it was trained on, but it believes that the training data encompasses “hundreds of terabytes or even petabytes of text data.”
Probing further, I learned that GPT has 175 billion parameters that run on “high-performance hardware infrastructure, including powerful GPUs (Graphics Processing Units) or TPUs (Tensor Processing Units).”
I verified this information, and can confirm that GPT was accurate.
What does this mean?
ChatGPT is basically the world’s most expensive mad libs playing machine. Given a sentence fragment, ChatGPT will complete the sentence. In fact, ChatGPT is so good at mad libs that it can generate partial sentences and complete those sentences with information that makes sense (most of the time).
As absurd as expertly completing mad libs sounds, our friends at Carnegie Mellon University used the same strategy developing Watson. As you may recall, Watson destroyed Jeopardy! champions Ken Jennings and Brad Rutter. Watson was eventually defeated by Rush Holt, but it’s Jeopardy! performance provides plenty of evidence for the effectiveness of the complete the sentence strategy.
What allowed Watson to beat Jeopardy! champions and what separates Watson from basic Google is the ability to put the information in context. The list of words, typically nouns, that are inputted into Boolean-based, keyword, search engines necessarily lack context. These search engines use other information to infer the context of the search. For example, Google uses the click frequency of results from users with similar queries to rank results. This works great for searches where many people are looking for the same answer to their query.
Google would be horrible at Jeopardy!, however, because the questions (nee answers) posed to Jeopardy! contestants are uncommon. Jeopardy’s format, responding in the form of a question, creates additional challenges that Google can’t easily overcome.

Google is also not great for finding information that is not commonly searched or things that may or may not actually exist. These types of searches require a different strategy such as using the classification of information to infer context. Luckily for lawyers, law librarians have been classifying information for almost 150 years using Shepard’s Citations and West’s key number system. These systems allow lawyers to quickly find related case law because a human has decided that the cases share context. Similarly, patents have been classified for decades using various classifications, most recently, CPC (Cooperative Patent Classification), which provides context for the search.
ChatGPT, Watson, and other AI systems are able to extract context from a natural language query, reducing the need for a robust classification system. Understanding context allowed Watson to quickly and correctly respond to Jeopardy! queries.
Embeddings and Neural Networks
Many AI systems use word embeddings to understand context. Word embeddings are vectors that are generated by language models (generally neural nets) that represent the words and phrases of a natural language query in real numbers. Embedding vectors typically use features of the target word, e.g. is it a noun, noun phrase, verb, etc. and words surrounding the target word to infer the meaning to the term in context. Embeddings are then mapped in “vector space,” with embeddings that are close to one another having similar meanings.
Modern embeddings distinguish similar terms that are used in different contexts without classification. For example, “nail” used in construction will map to a different point in vector space than a “nail” on a human hand or a “current” in an electric wire will map to a different vector space location than a “current” in the ocean based on the words surrounding these terms. Because embeddings can divine context, embeddings generated from a natural language query make searching much more precise.
Learn more here.
Like Rush Holt, ChatGPT became good at finding information by being exposed to and remembering a lot of information. Unfortunately, “remembering” information is a limitation of neural nets. Neural nets are limited by the number of nodes that can be trained before the output gets sketchy. As these models are exposed to information that is different from the data it was trained on, the embeddings are less reliable.
Transformers and Long-Range Dependencies
In technical terms, neural nets have trouble handling “long-range dependencies” in language. “Long-range dependence” defines the rate of decay of statistical dependence of two points with increasing time interval or spatial distance between the points. Basically, neural networks are less likely to correctly complete a sentence if it was exposed to the correct answer earlier in the training process than more recently. This makes training inefficient and reduces the amount of training data the model is able to ingest. As a very simple example, consider two sentences: “Betty has a dog” and “Betty has a very big brown dog”. For a simple network, the extra words in the second sentence give the network time to forget about “Betty” before it encounters “dog”. Modern large language models (LLMs) can handle much longer pieces of text, but ultimately the problem still arises. For this reason, neural nets trained on patent data are typically very good at certain types of technology, and not so good at others. Creating a neural net that can handle all types of technology requires a neural net that is beyond the current practical node limit.
Transformers used in large language models like ChatGPT dramatically improve the model’s “memory.” Transformer architecture addressed these limitations by leveraging “self-attention” mechanisms to process and encode input sequences in parallel, effectively improving long term memory of large language models like BERT and GPT-3. This reduces training time and improves performance.
The self-attention mechanism allows the model to weigh the importance of different words in a sentence when generating representations for each word. Both transformers and neural nets encode each word of the sentence. Unlike simpler neural nets, however, transformers calculate an attention score for each word. Words with higher scores are deemed more relevant for understanding the current word, capturing long-range dependencies. Transformer embeddings also use positional arguments that encode the relative position of each word in the input sequence.
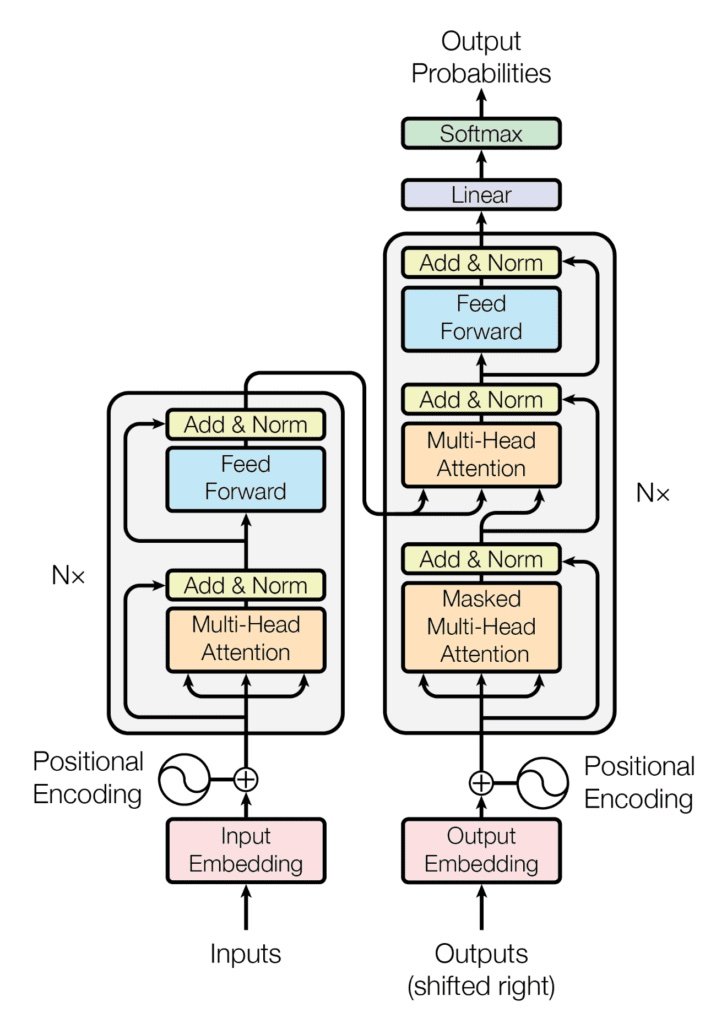
After self-attention, the transformer passes the representations through a neural network for further processing. Adding self-attention to the neural network, allows transformers to create embeddings that are contextually enriched compared to previous neural nets, capturing complex language patterns and long-range dependencies. Transformer architecture also allows for neural nets with more nodes, theoretically, allowing for language models that can handle all types of technology.
ChatGPT’s ability to generate readable text and mimic the style and tone of authors, speakers, and various other characters has taken center stage. Legal professionals whose primary job is to draft documents that have consistent content and form (e.g. basic contracts) are rightly concerned that the need for their services will diminish. At the same time, these models will provide lower cost access to legal information and basic contracts to underserved communities.
In Part 2, we’ll look at how generative AI will impact the business of law from the perspective of both legal service providers and clients.